
一、ELK简介
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack。
Elastic Stack包含:
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
详细可参考Elasticsearch权威指南
Logstash主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。目前Beats包含六种工具:
Packetbeat: 网络数据(收集网络流量数据)
Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat: 日志文件(收集文件数据)
Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
Auditbeat:审计数据 (收集审计日志)
Heartbeat:运行时间监控 (收集系统运行时的数据)
ELK官网:https://www.elastic.co/cn/
中文指南:https://www.gitbook.com/book/chenryn/elk-stack-guide-cn/details
1、ELK架构图
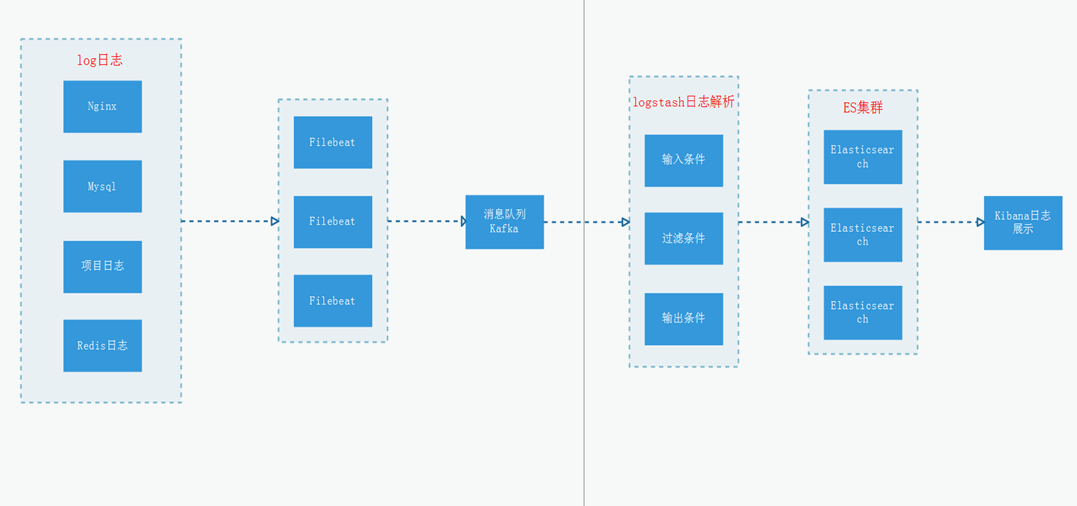
2、环境准备
操作系统:CentOS Linux release 7.8.2003 (Core)
服务器IP:192.168.0.4
3、软件版本
Elasticsearch:elasticsearch-7.5.1-linux-x86_64.tar.gz
Kibana:kibana-7.5.1-linux-x86_64.tar.gz
Logstash:logstash-7.5.1.tar.gz
Filebeat:filebeat-7.5.1-linux-x86_64.tar.gz
JDK:jdk-11.0.1_linux-x64_bin.tar.gz
Zookeeper:zookeeper-3.4.10.tar.gz
Kafka:kafka_2.12-2.5.0.tgz
二、基础环境配置
1、关闭防火墙和selinux
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
[root@localhost ~]# setenforce 0
[root@localhost ~]# sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
2、内核优化
[root@localhost ~]# vim /etc/security/limits.conf
# 在文件最后添加以下内容
* soft nofile 65537
* hard nofile 65537
* soft nproc 65537
* hard nproc 65537
[root@localhost ~]# vim /etc/security/limits.d/20-nproc.conf
# 配置以下内容
* soft nproc 4096
[root@localhost ~]# vim /etc/sysctl.conf
# 配置以下内容
net.ipv4.tcp_max_syn_backlog = 65536
net.core.netdev_max_backlog = 32768
net.core.somaxconn = 32768
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_fin_timeout = 120
net.ipv4.tcp_keepalive_time = 120
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.tcp_max_tw_buckets = 30000
fs.file-max=655350
vm.max_map_count = 262144
net.core.somaxconn= 65535
net.ipv4.ip_forward = 1
net.ipv6.conf.all.disable_ipv6=1
# 执行sysctl -p命令使其生效
[root@localhost ~]# sysctl –p
3、安装JDK环境
[root@localhost ~]# wget https://mirrors.yangxingzhen.com/jdk/jdk-11.0.1_linux-x64_bin.tar.gz
[root@localhost ~]# tar zxf jdk-11.0.1_linux-x64_bin.tar.gz -C /usr/local
#配置/etc/profile,添加以下内容
[root@localhost ~]# vim /etc/profile
export JAVA_HOME=/usr/local/jdk-11.0.1
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOMR/bin
[root@localhost ~]# source /etc/profile
#看到如下信息,java环境配置成功
[root@localhost ~]# java -version
java version "11.0.1" 2018-10-16 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.1+13-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.1+13-LTS, mixed mode)
4、创建ELK用户
[root@localhost ~]# useradd elk
三、安装Zookeeper
1、下载Zookeeper包
[root@localhost ]# wget -c http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
2、解压安装配置Zookeeper
[root@localhost ]# tar zxf zookeeper-3.4.10.tar.gz
[root@localhost ]# mv zookeeper-3.4.10 /usr/local/zookeeper
[root@localhost ]# cd /usr/local/zookeeper/
[root@localhost zookeeper]# mkdir -p data
[root@localhost zookeeper]# mkdir -p logs
【注意】:如果不配置dataLogDir,那么事务日志也会写在data目录中。这样会严重影响zookeeper的性能。因为在zookeeper吞吐量很高的时候,产生的事务日志和快照日志太多。
[root@localhost zookeeper]# cd conf/
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg
[root@localhost conf]# vim zoo.cfg
#服务器之间或客户端与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
#集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)
initLimit=10
#集群中flower服务器(F)跟leader(L)服务器之间的请求和答应最多能容忍的心跳数
syncLimit=5
#客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求
clientPort=2181
#存放数据文件
dataDir=/usr/local/zookeeper/data
#存放日志文件
dataLogDir=/usr/local/zookeeper/logs
#Zookeeper cluster,2888为选举端口,3888为心跳端口
#服务器编号=服务器IP:LF数据同步端口:LF选举端口
server.1=192.168.0.4:2888:3888
[root@localhost conf]# echo "1" > /usr/local/zookeeper/data/myid
5、启动Zookeeper服务
[root@localhost conf]# /usr/local/zookeeper/bin/zkServer.sh start
四、安装Kafka
1、下载Kafka软件包
[root@localhost ~]# wget -c https://www.apache.org/dyn/closer.cgi?path=/kafka/2.5.0/kafka_2.12-2.5.0.tgz
2、解压Kafka软件包
[root@localhost ~]# tar xf kafka_2.12-2.5.0.tgz
[root@localhost ~]# mv kafka_2.12-2.5.0 /usr/local/kafka
3、配置Kafka
[root@localhost ~]# vim /usr/local/kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.0.4:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=10
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.0.4:2181
zookeeper.connection.timeout.ms=60000
group.initial.rebalance.delay.ms=0
4、启动Kafka服务
注:需要等待Zookeeper服务器启动再启动Kafka,不然会报错
[root@localhost ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
五、安装elasticsearch
1、创建持久化目录及Logs日志目录
[root@localhost ~]# mkdir -p /data/elasticsearch/{data,logs}
2、下载elasticsearch软件包
[root@localhost ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-linux-x86_64.tar.gz
3、解压并重命名
[root@localhost ~]# tar xf elasticsearch-7.5.1-linux-x86_64.tar.gz
[root@localhost ~]# mv elasticsearch-7.5.1 /usr/local/elasticsearch
4、修改elasticsearch.yml配置文件,文件内容如下
[root@localhost ~]# vim /usr/local/elasticsearch/config/elasticsearch.yml
# 集群名称
cluster.name: es
# 节点名称
node.name: es-master
# 存放数据目录,先创建该目录
path.data: /data/elasticsearch/data
# 存放日志目录,先创建该目录
path.logs: /data/elasticsearch/logs
# 节点IP
network.host: 0.0.0.0
# tcp端口
transport.tcp.port: 9300
# http端口
http.port: 9200
# 主合格节点列表,若有多个主节点,则主节点进行对应的配置
cluster.initial_master_nodes: ["192.168.0.4:9300"]
# 是否允许作为主节点
node.master: true
# 是否保存数据
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: false
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 配置X-Pack
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
5、ELK用户授权
[root@localhost ~]# chown -R elk.elk /usr/local/elasticsearch/
[root@localhost ~]# chown -R elk.elk /data/elasticsearch/*
6、启动elasticsearch服务(第一次先测试好然后再加-d后台启动)
[root@localhost ~]# su - elk
[elk@localhost ~]$ /usr/local/elasticsearch/bin/elasticsearch
7、后台启动elasticsearch服务
[elk@localhost ~]$ /usr/local/elasticsearch/bin/elasticsearch -d
8、监控检测
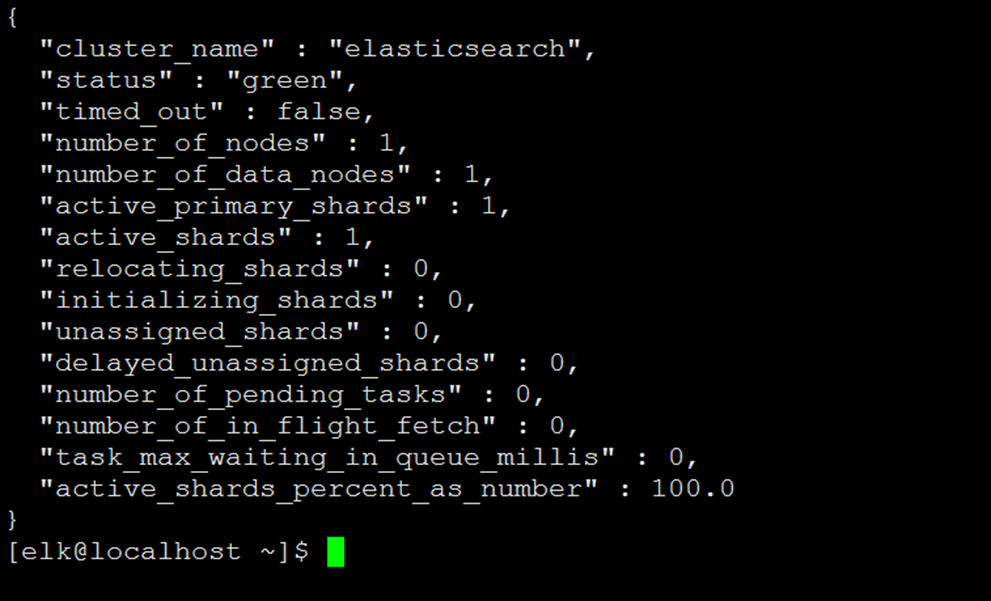
[elk@localhost ~]$ curl -X GET 'http://192.168.0.4:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1,
"active_shards" : 1,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# status=green 表示服务正常
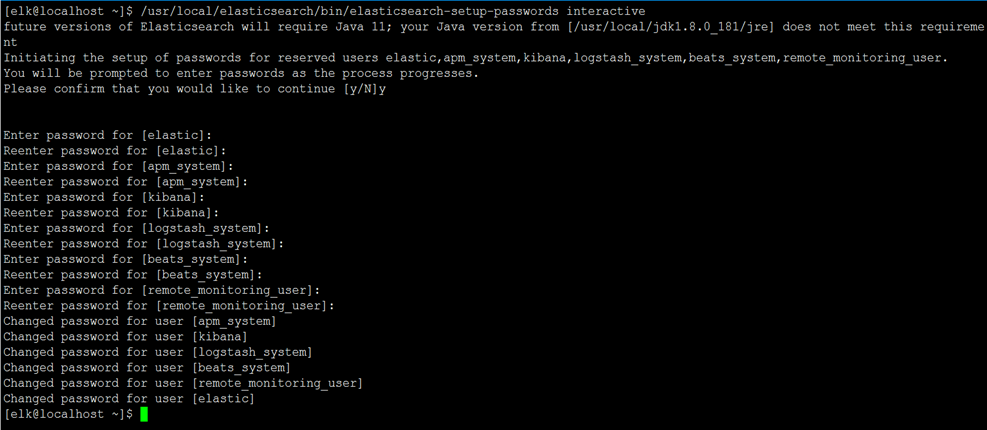
9、ElasticSearch配置用户名密码
[elk@localhost ~]$ /usr/local/elasticsearch/bin/elasticsearch-setup-passwords interactive
注:这里密码设置www.yangxingzhen.com
注:配置了密码之后获取集群状态命令如下
[elk@localhost ~]$ curl --user elastic:www.yangxingzhen.com -X GET 'http://192.168.0.4:9200/_cluster/health?pretty'
10、Elasticsearch常用命令
curl -XDELETE 'http://host.IP.address:9200/logstash-*' 删除索引(后面为索引名称)
curl -XGET 'host.IP.address:9200/_cat/health?v&pretty' 查看集群状态
curl -XGET 'host.IP.address:9200/_cat/indices?v&pretty' 查看索引
六、安装Kibana
1、下载Kibana软件包
[root@localhost ~]$ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.5.1-linux-x86_64.tar.gz
2、解压Kibana软件包并重命名
[root@localhost ~]$ tar xf kibana-7.5.1-linux-x86_64.tar.gz
[root@localhost ~]$ mv kibana-7.5.1-linux-x86_64 /usr/local/kibana
3、配置Kibana配置文件
[root@localhost ~]$ vim /usr/local/kibana/config/kibana.yml
#配置内容如下
# 配置kibana的端口
server.port: 5601
# 配置监听ip
server.host: "192.168.0.4"
# 配置es服务器的ip,如果是集群则配置该集群中主节点的ip
elasticsearch.hosts: ["http://192.168.0.4:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "www.yangxingzhen.com"
# 配置kibana的日志文件路径,不然默认是messages里记录日志
logging.dest: /usr/local/kibana/logs/kibana.log
# 配置为中文
i18n.locale: "zh-CN"
4、创建日志目录并授权
[root@JDCloud_Server ~]# mkdir /usr/local/kibana/logs
[root@JDCloud_Server ~]# chown -R elk.elk /usr/local/kibana/
5、启动Kibana服务
[root@localhost ~]# su - elk
# 前台启动
[elk@localhost ~]$ /usr/local/kibana/bin/kibana
# 后台启动
[elk@localhost ~]$ /usr/local/kibana/bin/kibana &
温馨提示:可以先前台启动查看日志,正常之后在后台启动。
七、安装filebeat
1、下载filebeat软件包
[root@localhost ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.5.1-linux-x86_64.tar.gz
2、解压并重命名
[root@localhost ~]# tar xf filebeat-7.5.1-linux-x86_64.tar.gz
[root@localhost ~]# mv filebeat-7.5.1-linux-x86_64 /usr/local/filebeat
3、编辑filebeat.yml配置文件,配置内容如下
[root@localhost ~]# vim /usr/local/filebeat/filebeat.yml
#========= Filebeat inputs ==========
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/elasticsearch/logs/elasticsearch.log
multiline:
pattern: '^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}'
negate: true
match: after
fields:
log_topics: elasticsearch-log
logtype: elasticsearch
output.kafka:
enabled: true
hosts: ["192.168.0.4:9092"]
topic: '%{[fields][log_topics]}'
4、创建Filebeat日志目录
[root@localhost ~]# mkdir /usr/local/filebeat/logs
[root@localhost ~]# chown -R elk.elk /usr/local/filebeat
5、启动filebeat服务
[root@localhost ~]# su - elk
[elk@localhost ~]# cd /usr/local/filebeat
# 前台启动
[elk@localhost filebeat]$ ./filebeat -e -c filebeat.yml >>logs/filebeat.log
# 后台启动
[elk@localhost filebeat]$ nohup ./filebeat -e -c filebeat.yml >>logs/filebeat.log >/dev/null 2>&1 &
八、安装logstash
1、下载软件包
[root@localhost ~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-7.5.1.tar.gz
2、解压并重命名
[root@localhost ~]# tar zxf logstash-7.5.1.tar.gz
[root@localhost ~]# mv logstash-7.5.1 /usr/local/logstash
3、创建elasticsearch.conf文件,添加以下内容
[root@localhost ~]# vim /usr/local/logstash/config/elasticsearch.conf
input {
kafka {
bootstrap_servers => "192.168.0.4:9092"
group_id => "logstash-group"
topics => ["elasticsearch-log"]
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
codec => json
}
}
filter {
if [fields][logtype] == "elasticsearch" {
json {
source => "message"
}
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level}" }
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss,SSS"]
target => "@timestamp"
}
}
}
output {
if [fields][logtype] == "elasticsearch" {
elasticsearch {
hosts => ["192.168.0.4:9200"]
user => "elastic"
password => "www.yangxingzhen.com"
action => "index"
index => "elasticsearch.log-%{+YYYY.MM.dd}"
}
}
}
4、启动logstash服务
[root@localhost ~]# chown -R elk.elk /usr/local/logstash
[root@localhost ~]# su - elk
# 前台启动
[elk@localhost ~]$ /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf/elasticsearch.conf
# 后台启动
[elk@localhost ~]$ cd /usr/local/logstash/bin && nohup ./logstash -f /usr/local/logstash/config/elasticsearch.conf >/dev/null 2>&1 &
九、访问Kibana
# 浏览器访问:http://192.168.0.4:5601,出现如下界面
# 输入前面设置的用户名和密码,出现如下界面
# 选择自己浏览,出现以下界面
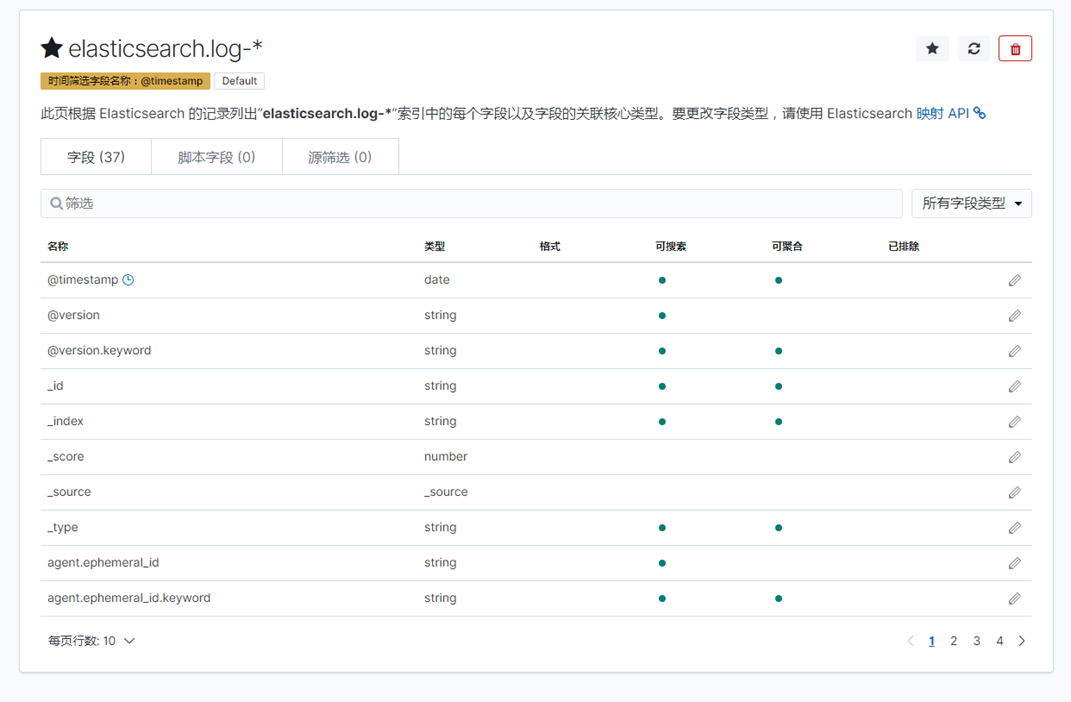
分别点击管理--》索引管理,这时候就能看到Elasticsearch的索引信息
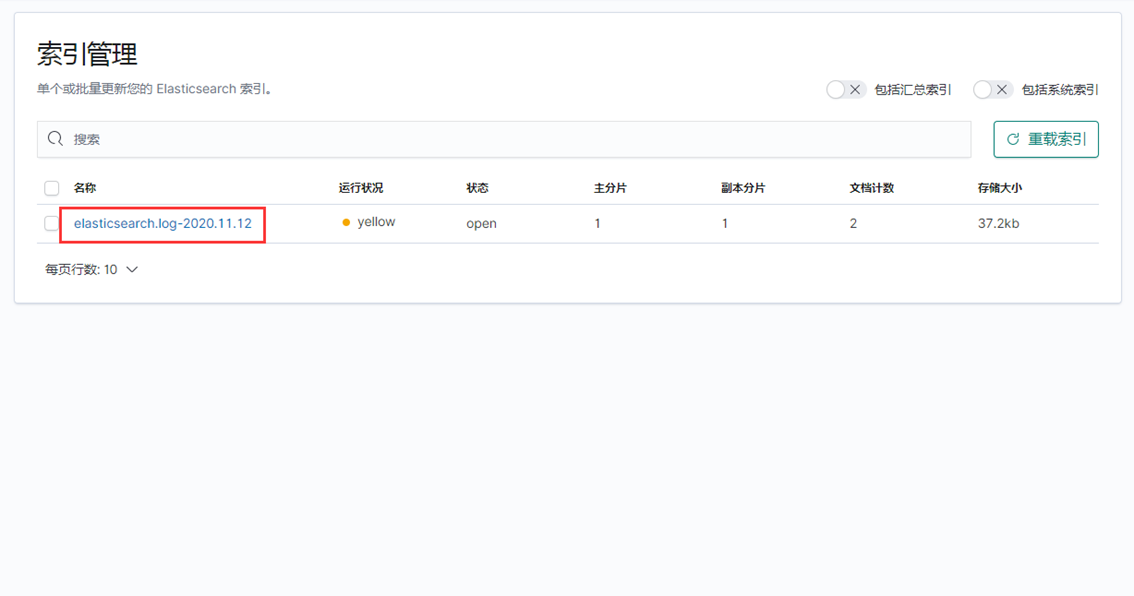
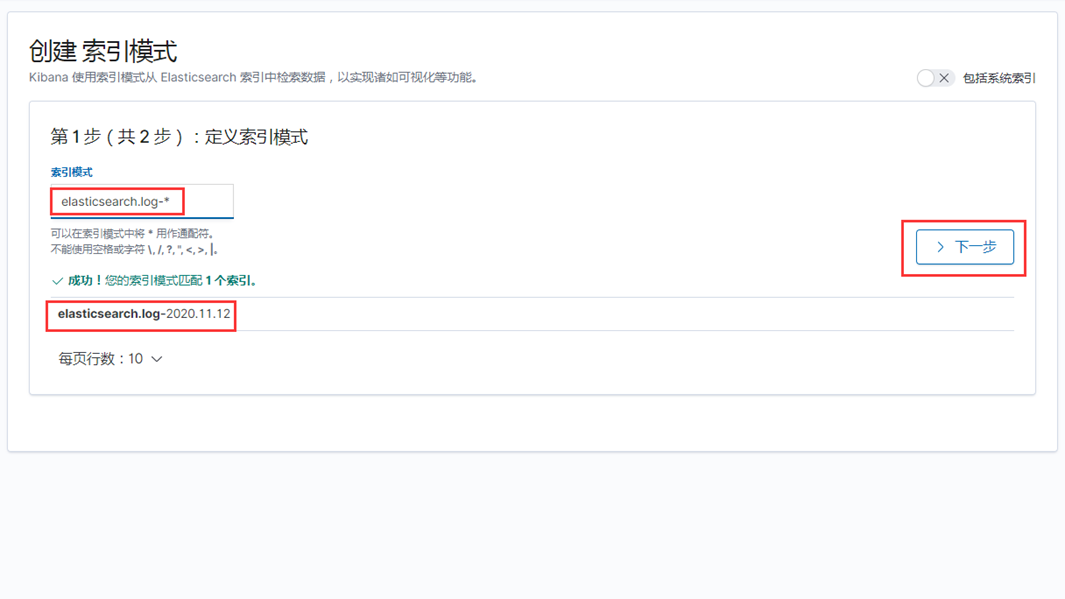
1、创建Elasticsearch日志索引
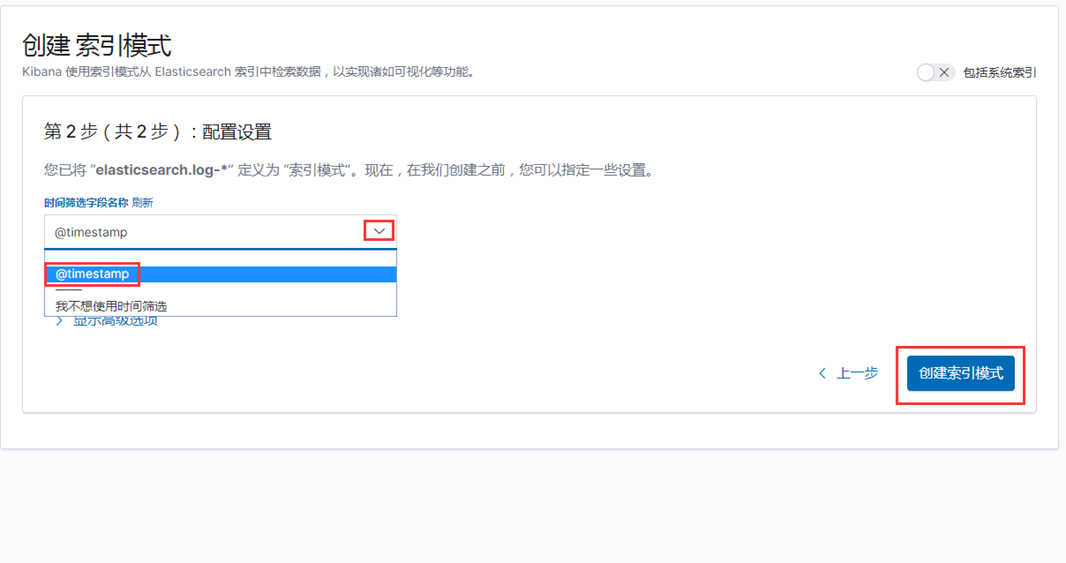
索引模式--->>创建索引模式,输入索引模式名称,点击下一步
2、点击Discover,就能看到日志数据了,如下图
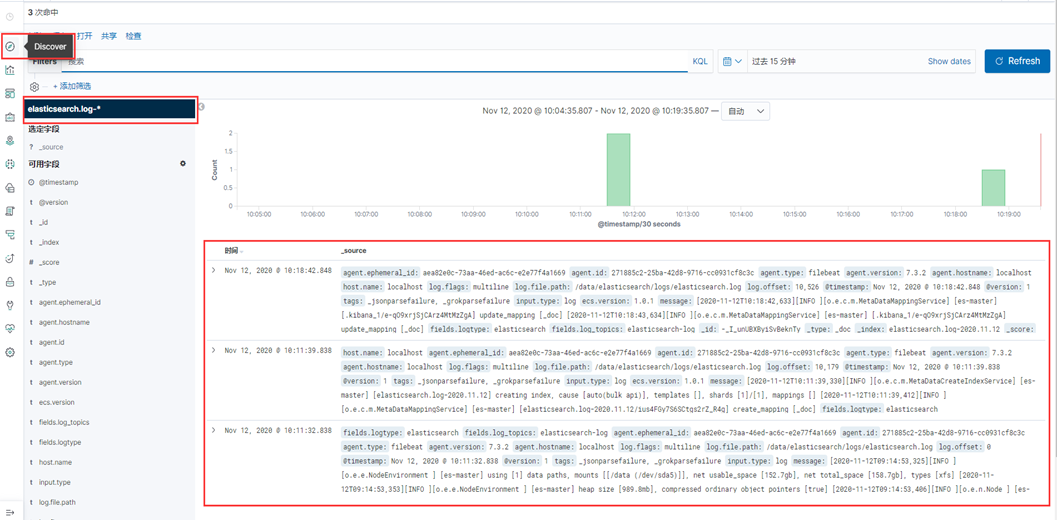
至此,ELK日志平台收集Elasticsearch日志搭建完成。
若文章图片、下载链接等信息出错,请在评论区留言反馈,博主将第一时间更新!如本文“对您有用”,欢迎随意打赏,谢谢!


请问中间件选择kafka和redis各自的优势是什么?各自适合的场景是哪种呢?
@ pppkq 这个问题呢,这两者区别,存储介质不同、性能不同、成本也不同,Redis数据是存储在内存,虽然有AOF和RDB的持久化方式,但是还是以内存为主。kafka存储在硬盘上,成本会比内存小很多,如果需要快速消费的话可以选择redis,如果觉得稳定可以选择kafka,这些都是需要结合当前项目去选择的,仅为参考。
场景: Kafka
如果你想要稳定的消息队列
如果你想要你发送过的消息可以保留一定的时间,并不是无迹可寻的时候
如果你无法忍受数据的丢失
如果速度不需要那么的快
如果需要处理数据量巨大的时候
场景: Redis
如果你的需求是快产快消的即时消费场景,并且生产的消息立即被消费者消费掉
如果速度是你十分看重的,比如慢了一秒好几千万这种
如果允许出现消息丢失的场景
如果你不需要系统保存你发送过的消息,做到来无影去无踪
如果需要处理的数据量并不是那么巨大
@ 小柒博客 多谢答复
不错噢